-
Oct '25Our extended journal paper Large Language Models acing Chartered Accountancy got accepted at SN Computer Science Journal. 🥳
-
Oct '25Our paper Large Language Models acing Chartered Accountancy got published at MoStart-2025, University of Mostar, Bosnia and Herzegovina, Europe (Scopus). 🥳
-
Sep '25Our paper Vaani: Transforming Healthcare and Enhancing Communication for the Deaf and Mute Community with Real-Time Translation got published at ICRTICC-2025, GCET, Delhi-NCR, India (Scopus). 👏
-
Aug '25Our paper Indian Sign Language Detection for Real-Time Translation using Machine Learning got published at RAIT-2025, IIT Dhanbad - Indian School of Mines, India (IEEE). 💫
-
July '25Successfully concluded my research internship with the 𝑶𝒖𝒕𝒓𝒆𝒂𝒄𝒉 𝑷𝒓𝒐𝒈𝒓𝒂𝒎 at 𝑰𝑰𝑰𝑻 𝑵𝒂𝒚𝒂 𝑹𝒂𝒊𝒑𝒖𝒓. Check out my LinkedIn post for more details! ✅
-
June '25Delivered a session on LLMs at IIIT Naya Raipur, covering theory and practicals. Details here! 👨🏫
-
May '25Got selected for the 𝑶𝒖𝒕𝒓𝒆𝒂𝒄𝒉 𝑰𝒏𝒕𝒆𝒓𝒏𝒔𝒉𝒊𝒑 𝑷𝒓𝒐𝒈𝒓𝒂𝒎 at 𝑰𝑰𝑰𝑇 𝑵𝒂𝒚𝒂 𝑹𝒂𝒊𝒑𝒖𝒓 !!! 🎊
-
May '25Joined Waterworks Agency LLC (Texas, United States) as an AI Specialist, working on AI automation and voice systems 😄!
-
Apr '25
-
Apr '25Our paper Large Language Models acing Chartered Accountancy got accepted at MoStart-2025 Conference 🥳!
-
Mar '25
-
Feb '25Presented our paper Vaani, at the ICRTICC-2025 Conference.
-
Feb '25Our book chapter, Challenges with Current Health Information Systems, will be published by CRC Press in their upcoming volume
-
Jan '25Our paper, Vaani has been accepted for publication at ICRTICC-2025 🥳.
-
Jan '25Acquired membership with the International Association of Engineers (IAENG).
-
Dec '24Our paper Indian Sign Language Detection for Real-Time Translation using ML got accepted at RAIT Conference 2025 🥳.
-
Nov '24Our research article, Legal Assist AI, has been published as our first preprint and is currently under review.
-
Nov '24Ranked in the top 3% of contributors in GSSOC-2024.
-
Sep '24Ranked 4th in ModelWiz: The ML Arena; Kaggle Competition hosted by DataPool Club.
-
Sep '24Selected as a Contributor for GirlScript Summer of Code 2024 Extended Edition! 🎉.
-
May '24Selected for AI Internship at Infosys Springboard, Bengaluru (Remote), India.
-
Sep '23Awarded Merit Scholarship for Academic Year 2022-2023.
-
Sep '22Joined Sharda University, Greater Noida for B.Tech in CS with specialization in Data Science and Analytics.

Jatin Gupta
Click to unscramble
Academic Email:
2rn2u2adh0g.sj6a@ta0.0i82n
Personal Email:
m@162016atgpjliangutac.om
About
I am a final-year undergraduate student at Sharda University, Greater Noida, majoring in Computer Science and Data Science. My academic pursuits focus majorly on Large Language Models (LLMs), especially for legal and financial applications.
I am currently engaged in a Research Internship at IIIT-Naya Raipur under Dr. Santosh Kumar, where I explore real-world deployments of AI in data-driven environments.
Last Summer, I interned at Infosys under Trapti Singhal, where I developed a time series–based demand forecasting model that improved forecast accuracy by 5% and presented the results to board-level stakeholders.
Under the guidance of Dr. Ali Imam Abidi, I co-developed Legal Assist AI, which outperformed GPT-3.5 on legal reasoning tasks. Building on that, I helped create CA-Ben, a benchmark for financial reasoning in LLMs, which I presented at MoStart 2025 in Bosnia and Herzegovina.
I have co-authored multiple book chapters in the field of AI, contributing to academic research and interdisciplinary knowledge sharing.
Please feel free to check out my resume.
I am currently engaged in a Research Internship at IIIT-Naya Raipur under Dr. Santosh Kumar, where I explore real-world deployments of AI in data-driven environments.
Last Summer, I interned at Infosys under Trapti Singhal, where I developed a time series–based demand forecasting model that improved forecast accuracy by 5% and presented the results to board-level stakeholders.
Under the guidance of Dr. Ali Imam Abidi, I co-developed Legal Assist AI, which outperformed GPT-3.5 on legal reasoning tasks. Building on that, I helped create CA-Ben, a benchmark for financial reasoning in LLMs, which I presented at MoStart 2025 in Bosnia and Herzegovina.
I have co-authored multiple book chapters in the field of AI, contributing to academic research and interdisciplinary knowledge sharing.
Please feel free to check out my resume.
News
Education
Sharda University, Greater Noida
September '22 - June '26
Awards: Merit Scholarship Awardee 2022-2023
Student Societies:
- Member | National Service Scheme (NSS)
Experience
Research Intern | IIIT Naya Raipur
May '25 - July '25
Currently working as a Research Intern at IIIT Naya Raipur under Dr. Santosh Kumar through the Outreach Internship Programme (OIP). I'm focused on research and development in Generative AI and NLP (Natural Language Processing), addressing real-world challenges in data-centric domains. The work involves exploring novel methods, contributing to research outputs, and collaborating on academic publication.
Artificial Intelligence Specialist | Waterworks Agency LLC
May '25 - July '25
At Waterworks Agency LLC (Texas), I build AI automation tools and voice assistants using platforms like Voiceflow and Google Gemini. I develop lead nurturing workflows and intelligent integrations across Make, Google Workspace, and Google Sheets. My focus is on streamlining operations with smart, data-driven systems that improve engagement and efficiency throughout clients and business owners.
Artificial Intelligence Intern | Infosys Springboard
May '24 - July '24
Our project, "Demand Forecasting for E-commerce", conducted under the guidance of Trapti Singhal at Infosys, involved designing a demand forecasting model using time series analysis, leading to a 5% improvement in product sales forecast reliability. I optimized the model through feature engineering and collaborated with a team of 10 to deliver a comprehensive presentation of our findings and methodology to board members, showcasing both technical and communication skills.
Publications
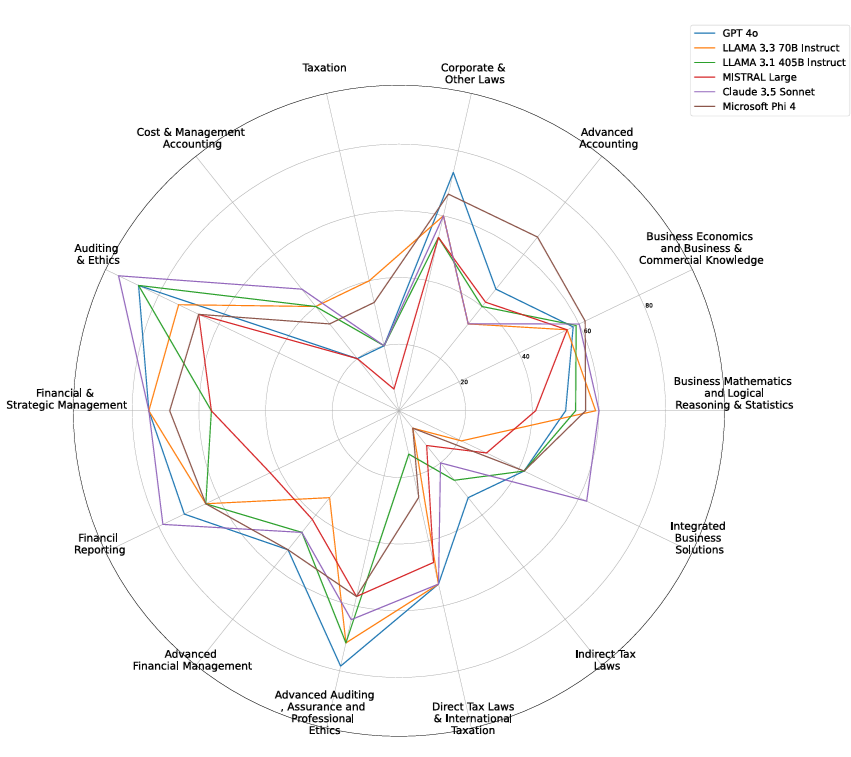
MOSTART-2025: International Conference on Digital Transformation in Education and Artificial Intelligence Applications
We introduce CA-Ben, a benchmark for testing the financial, legal, and quantitative reasoning of language models in the Indian context, using data from ICAI's Chartered Accountancy exams. Six top LLMs are evaluated, with GPT-4o and Claude 3.5 Sonnet leading in legal and conceptual tasks. However, challenges remain in numerical accuracy and legal interpretation, underscoring the need for hybrid reasoning and retrieval-augmented methods in financial AI.
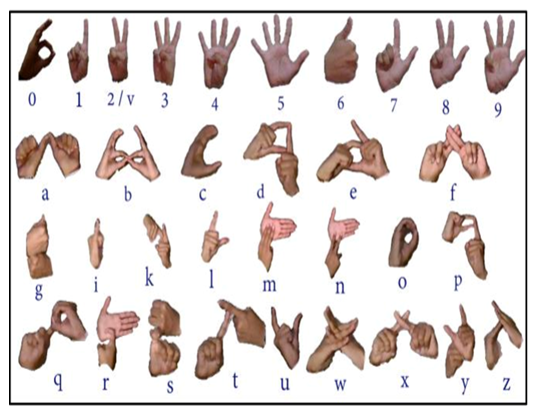
RAIT-2025: International Conference on Recent Advances in Information Technology
We propose a vision-based solution for Indian Sign Language (ISL) recognition to support the deaf and mute communities. Using CNNs and Mediapipe for hand gesture detection, our model achieves 99.95% accuracy on the ISL dataset. Evaluated with F1 score and precision-recall, the system offers a complete pipeline for inclusive communication technology.
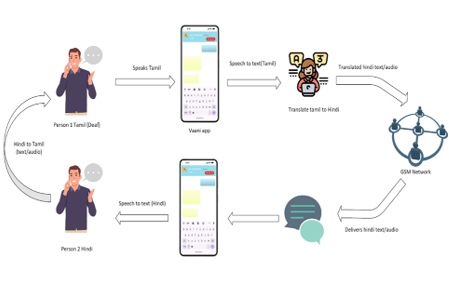
ICRTICC-2025: International Conference on Recent Trends in Intelligent Computing and Communication
We introduce Vaani, a real-time, multilingual communication tool for individuals with hearing and speech impairments, designed for critical settings like healthcare. It combines speech-to-text, text-to-speech, offline access, and secure encryption to ensure effective, accessible communication—especially in rural areas. Vaani enhances interaction, bridging communication gaps in both medical and everyday contexts.

arXiv - preprint.
We present Legal Assist AI, a transformer-based model built to enhance legal access in India. Trained on datasets like Lawyer_GPT_India and AIBE, it answers legal queries with high accuracy. In evaluations, it scored 60.08% on the AIBE, outperforming models like GPT-3.5 Turbo and Mistral 7B in legal reasoning and reliability. Unlike others, it minimizes hallucinations, making it suitable for real-world use. Aimed at both legal professionals and the public, future versions will support multilingual and case-specific queries.
Key Projects
Text to 3D
Text to 3D scene Generator is a web application that uses generative AI to generate 3D scenes and models from text descriptions. It integrates with Three.js for rendering, Azure OpenAI API for simpler models generation, and Tripo3D API for creating realistic 3D models. Built with a Flask backend and a modern HTML/CSS/JavaScript frontend, it allows users to create, view, interact with, and download 3D models through a responsive web interface.
CA-ThinkFlow
CA-ThinkFlow is an AI-powered financial consulting application designed to assist users with various financial queries. Built using Streamlit and Langchain, this application leverages advanced language models to provide accurate and context-aware responses to user questions related to finance. The system implements Retrieval Augmented Generation (RAG) to enhance response accuracy by referencing a curated knowledge base of financial documents and regulations. A robust fallback mechanism switches between different language models when confidence scores are low, ensuring reliable responses even for complex queries.

Digital Image Tampering Detection
The code establishes a robust framework for detecting tampered images using Error Level Analysis (ELA) and a Convolutional Neural Network (CNN). ELA highlights compression artifacts indicative of tampering, and images are preprocessed, normalized, and resized to a fixed dimension. The dataset, containing authentic and tampered images, is labeled and split into training, validation, and test sets. Data augmentation is applied to enhance generalization, and the model is trained with early stopping. Evaluation includes confusion matrices, accuracy, precision, and F1-scores, achieving ~90% accuracy. The pipeline also visualizes tampered regions and predicts authenticity with high confidence, demonstrating its efficacy for digital image forensics.
More projects can be found on GitHub